Hello! I am an upcoming Ph.D graduate from KAIST AI, advised by Jaegul Choo.
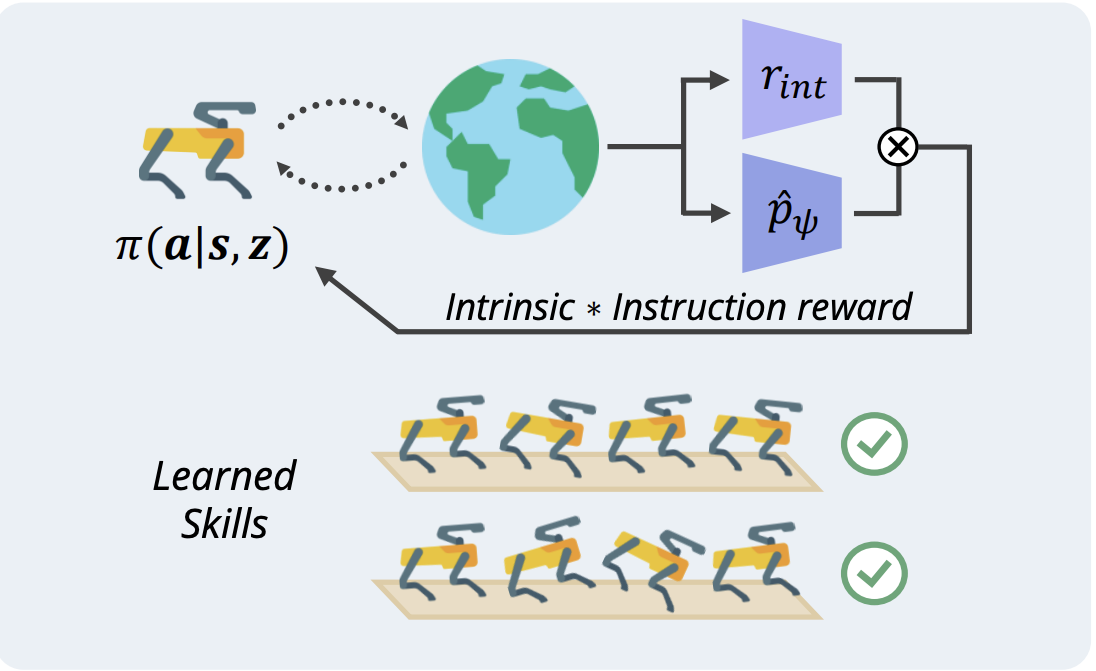
My research interests lies in developing scalable robotic foundation models that can continually adapt, generalize, and solve diverse real-world tasks.
Currently, I'm leading Davian Robotics, a subgroup of Davian Lab focused on open-source robotic research.
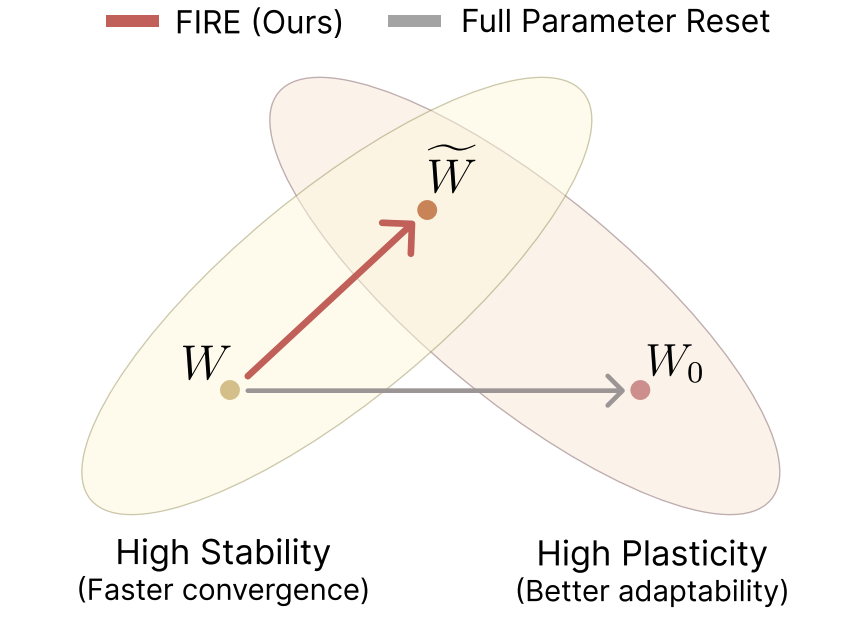
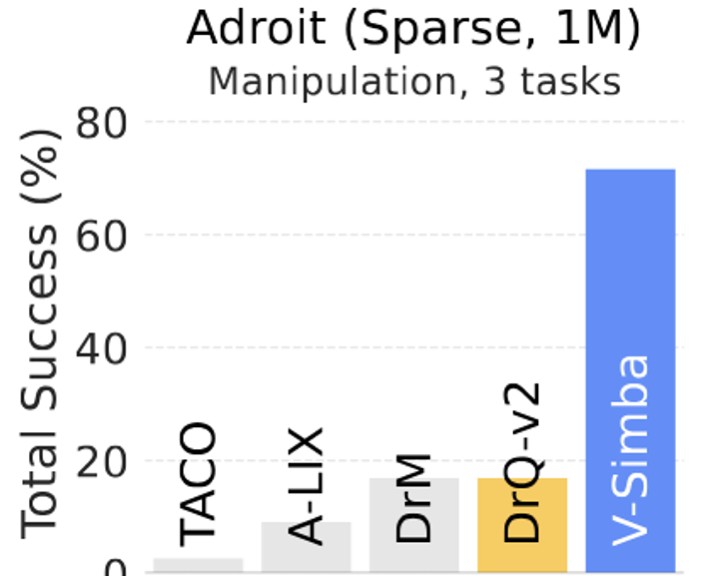
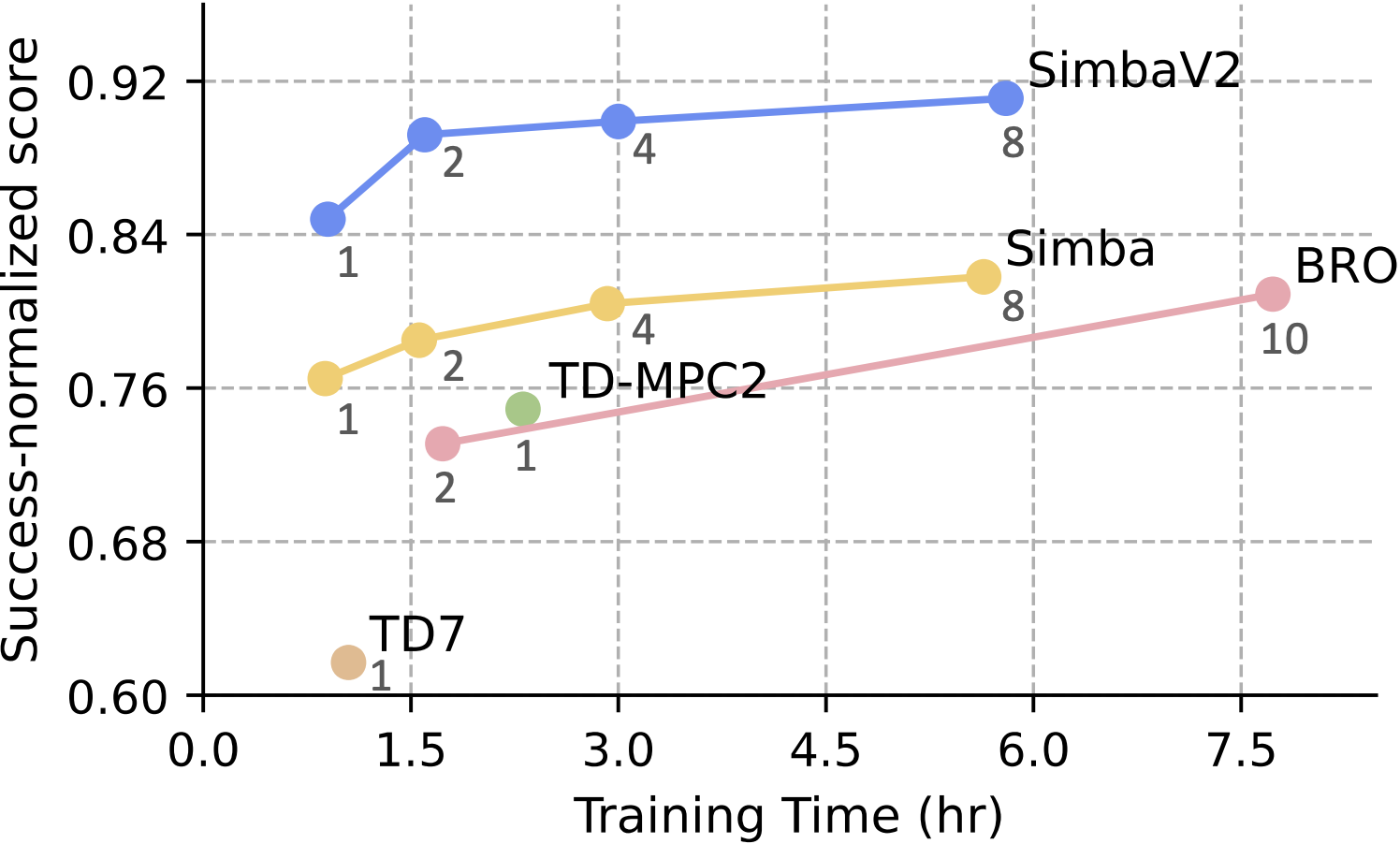
I’m best known for the Simba series (1, 2), a set of neural network architectures for scalable reinforcement learning in robotics.
I enjoy collaborating with interdisciplinary teams and mentoring junior researchers. Feel free to reach out if you'd like to collaborate :)







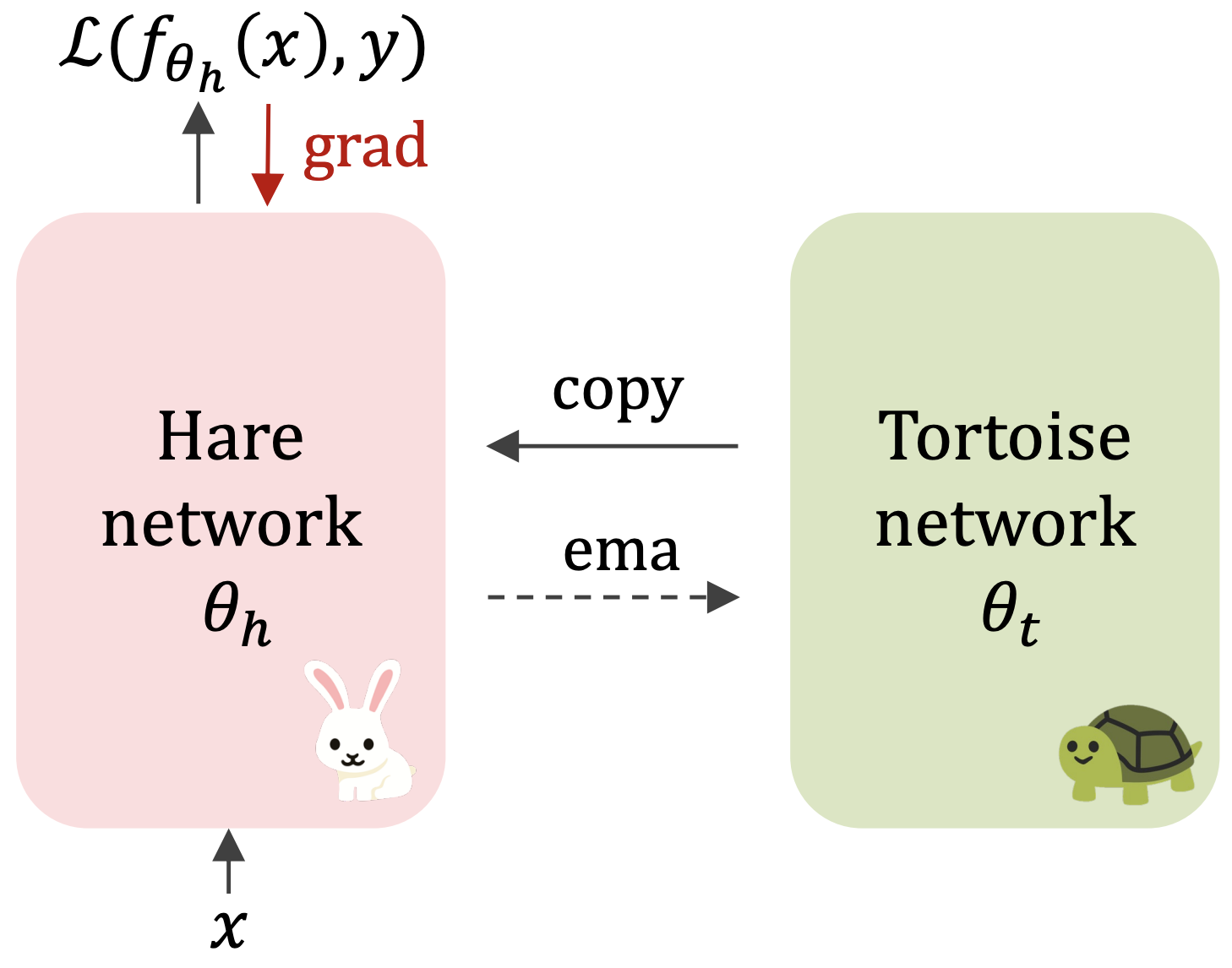
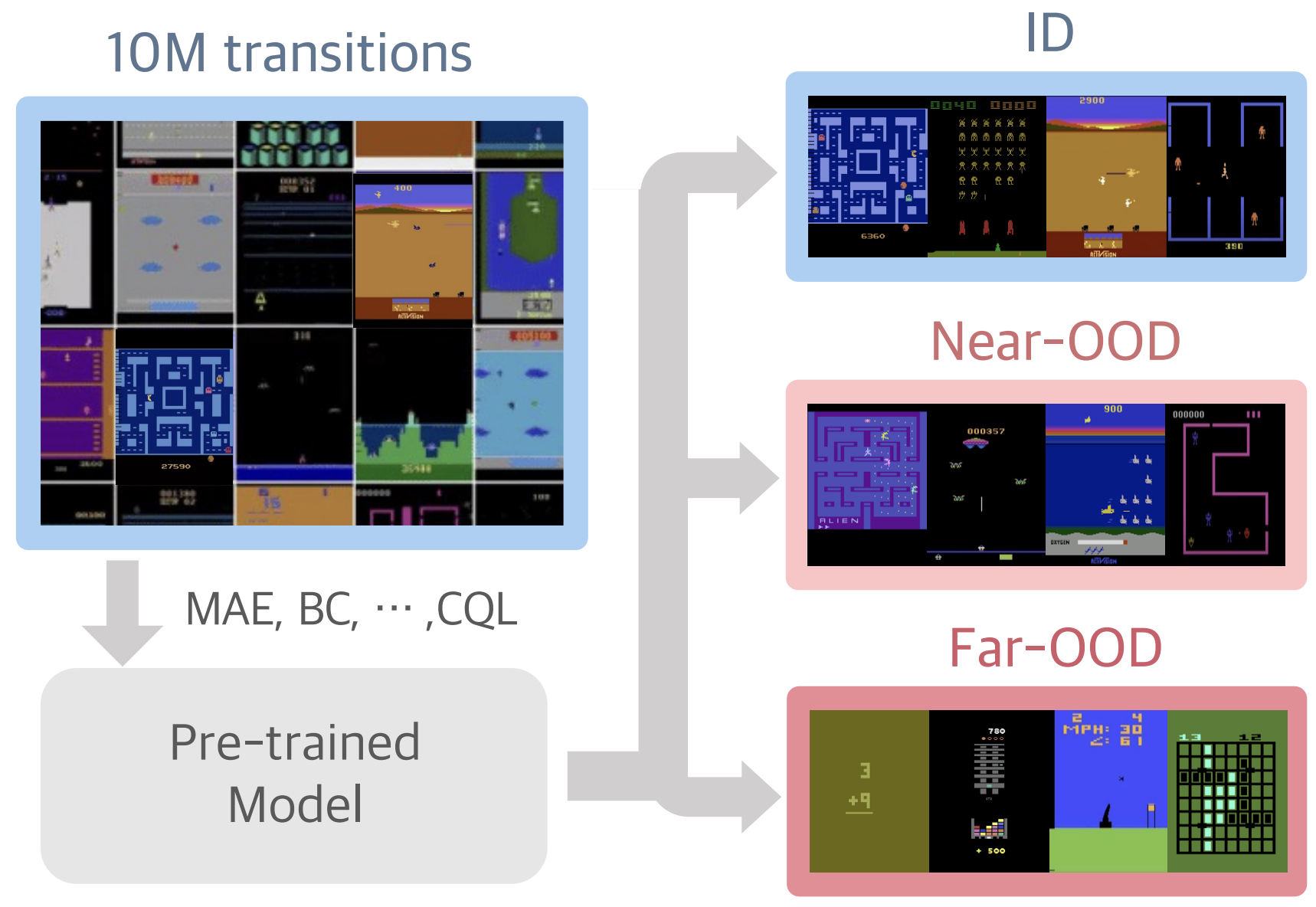
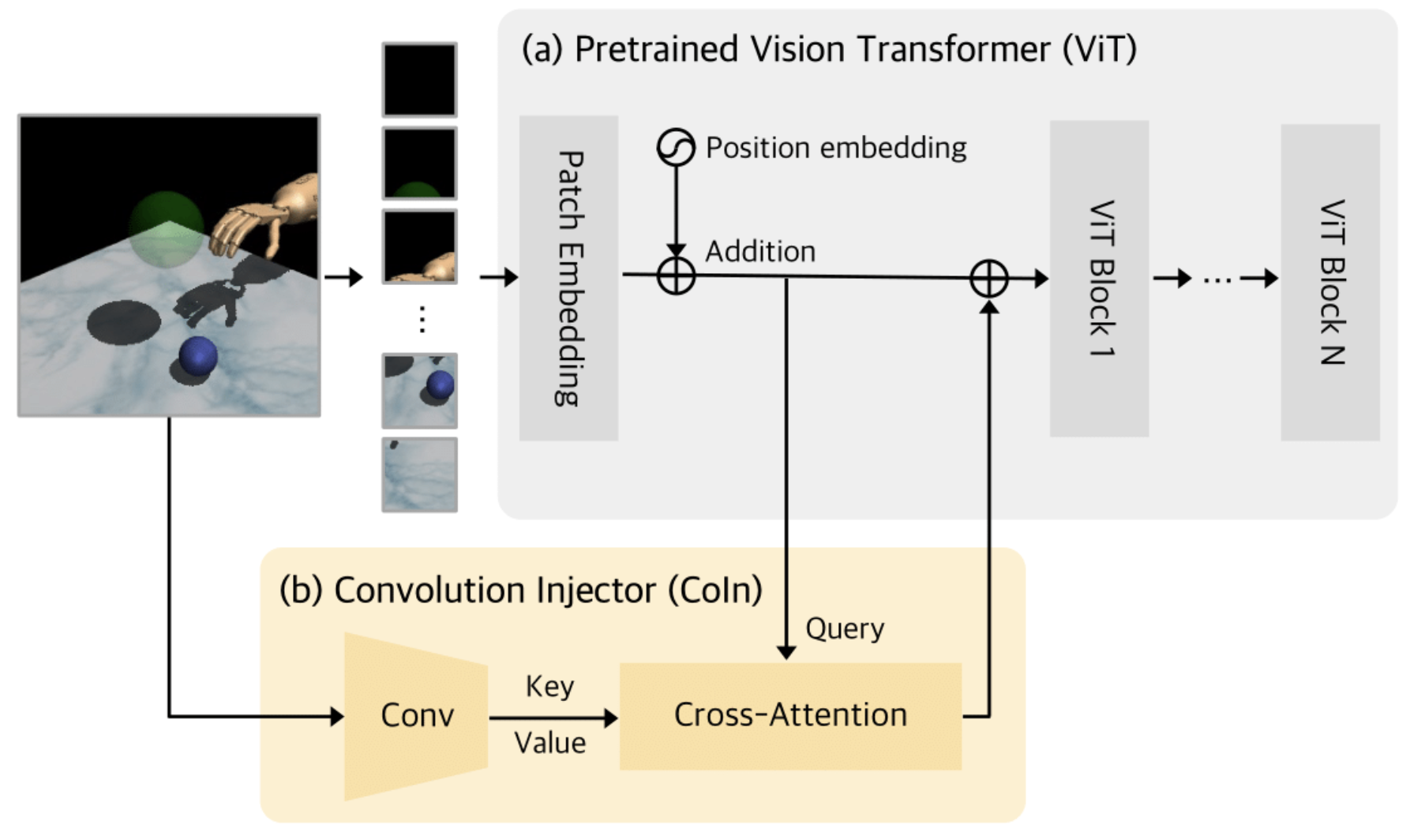
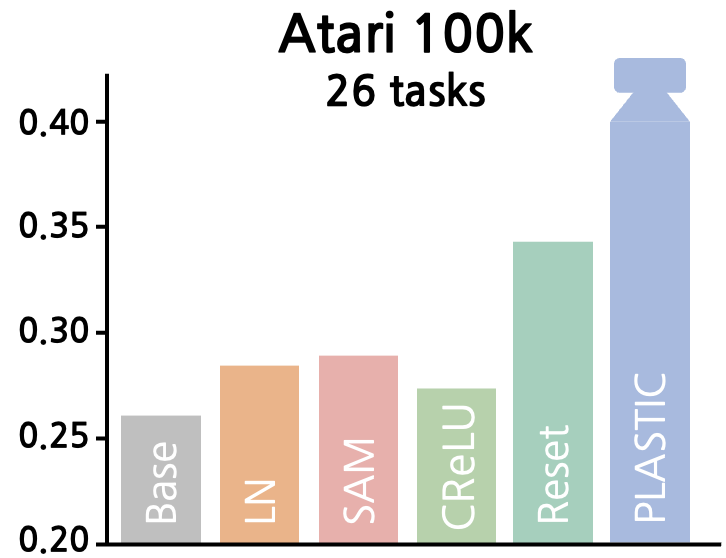

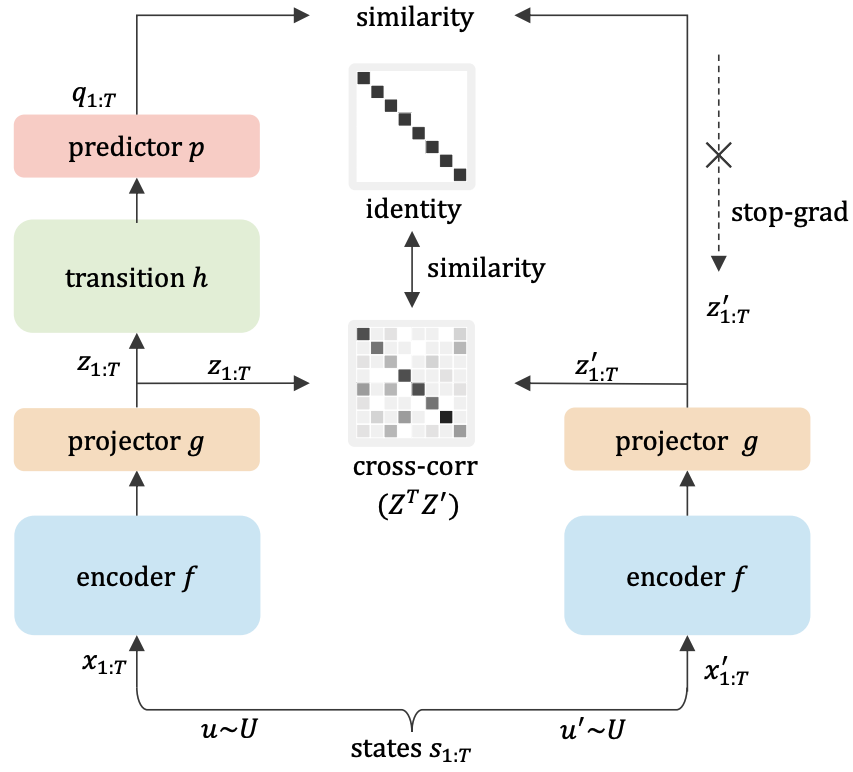
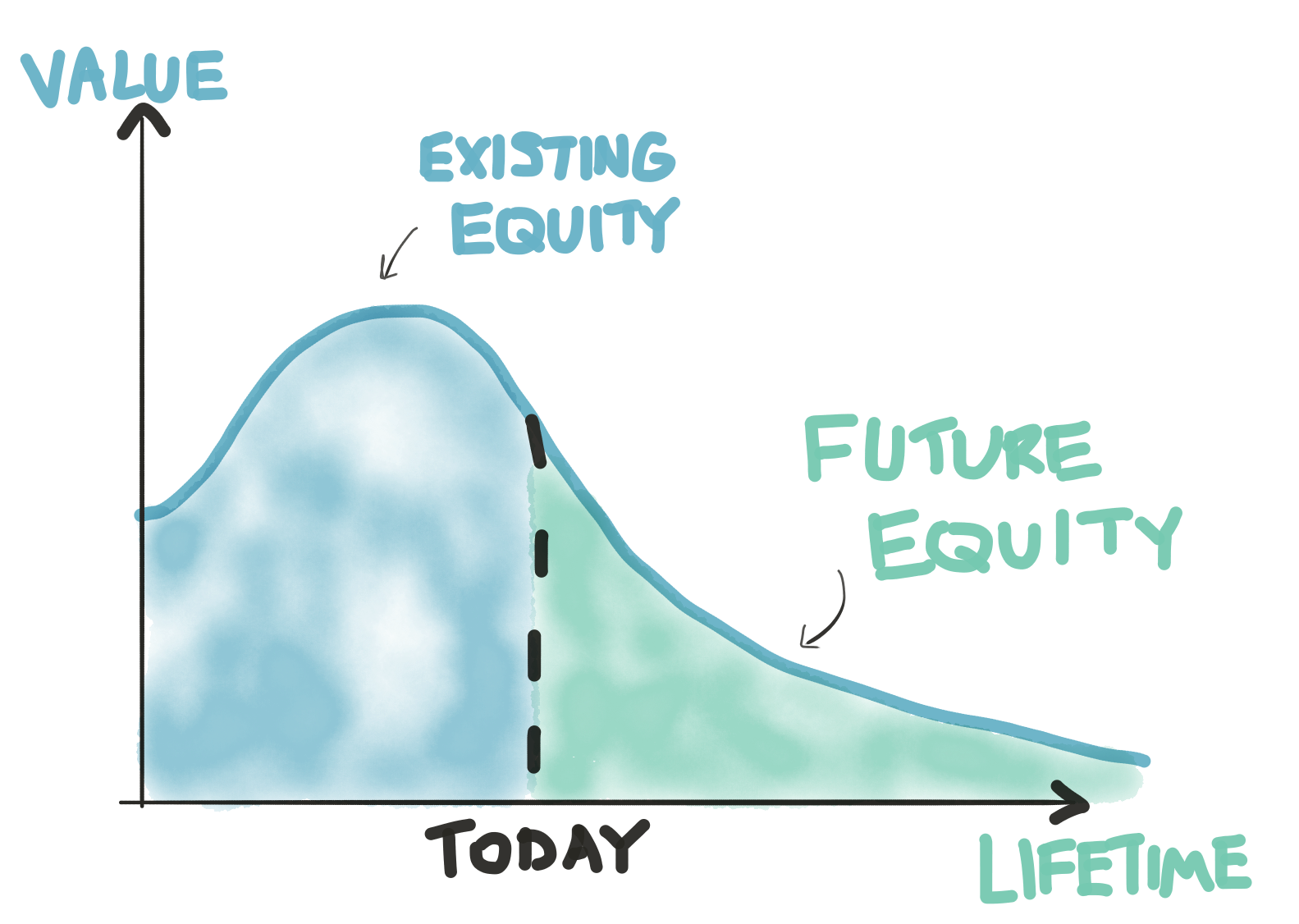






{kind=link}
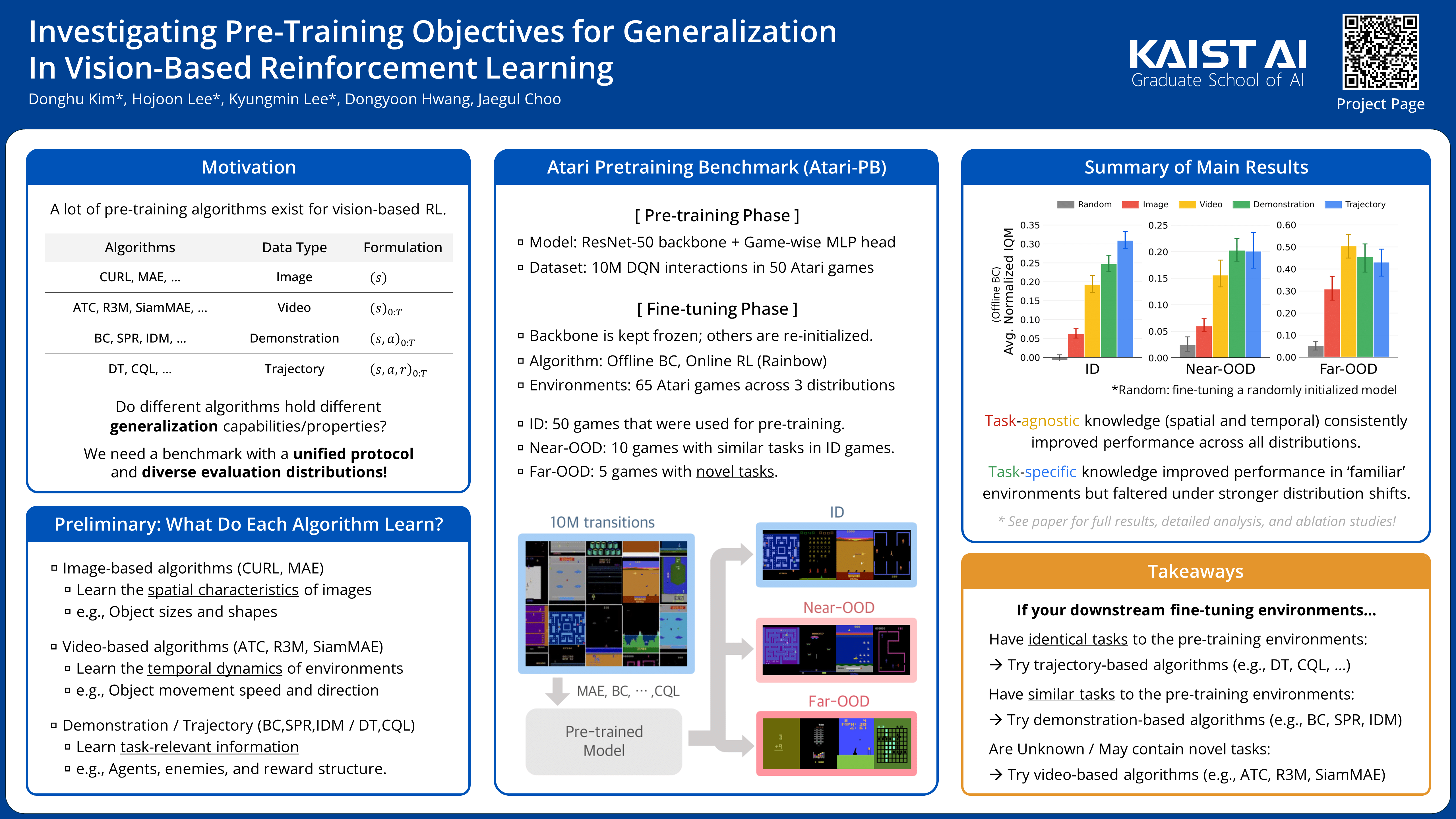{kind=link}